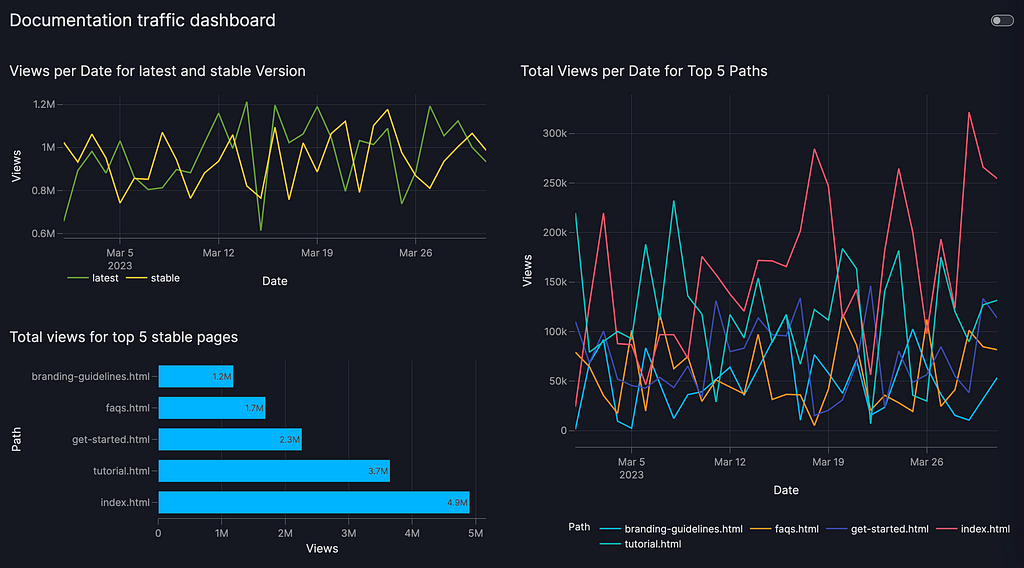
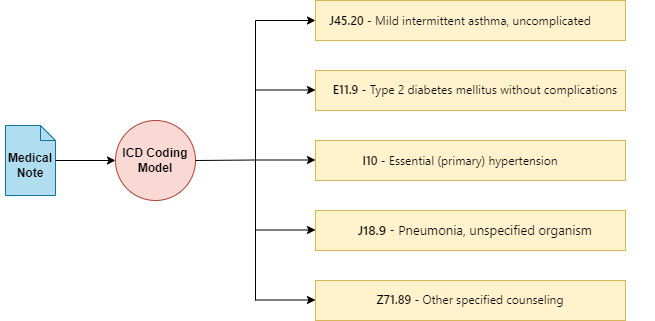
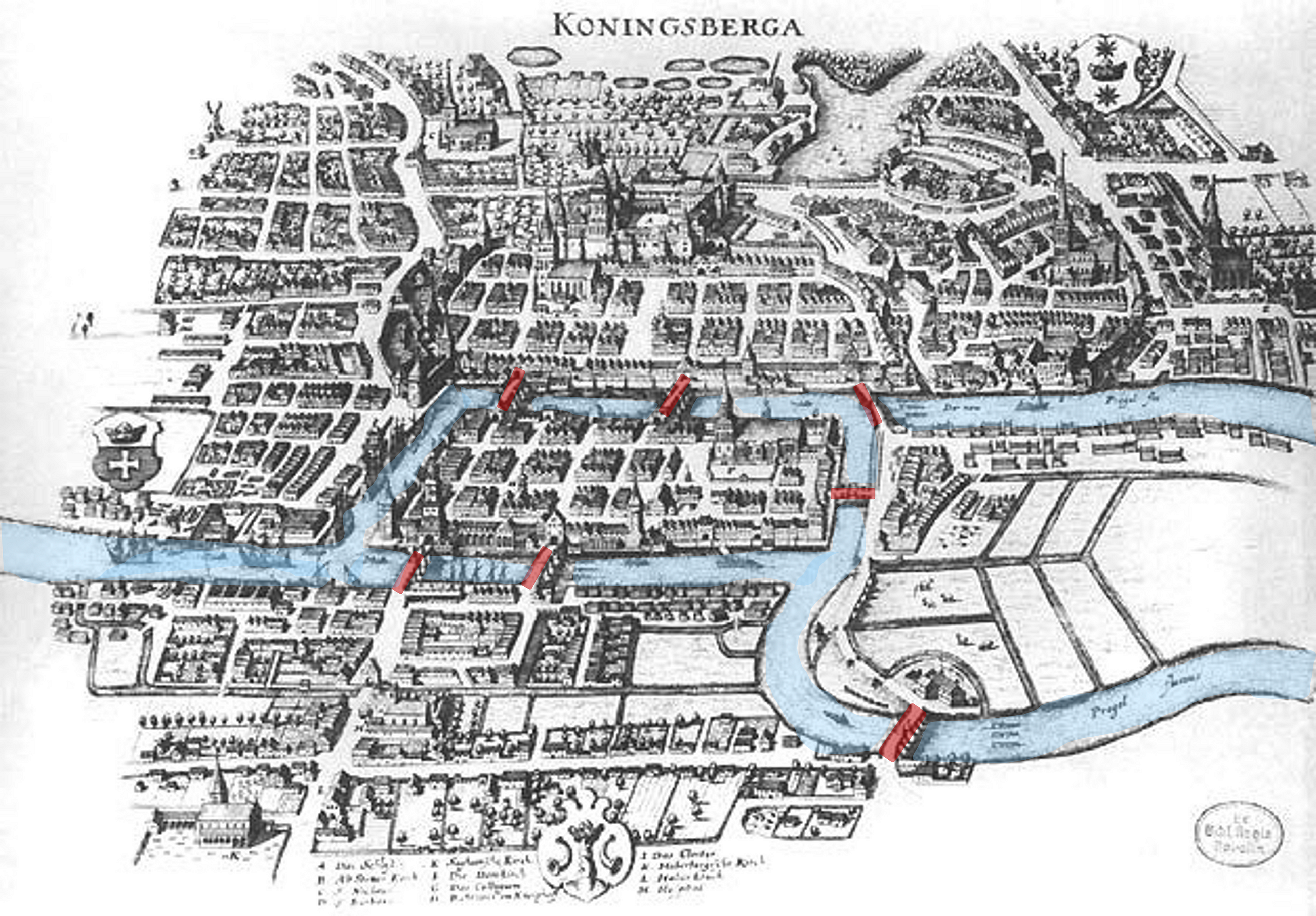
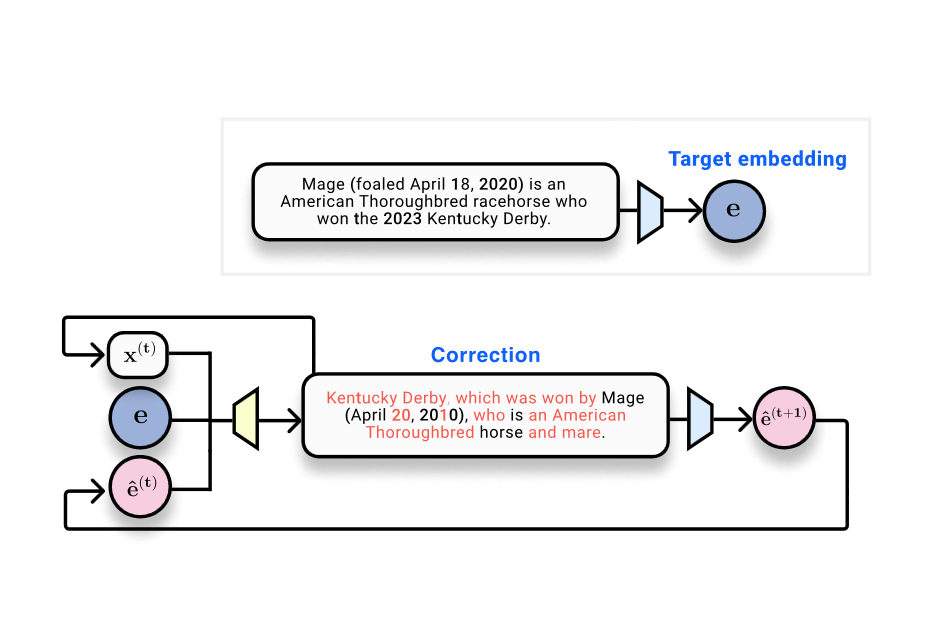
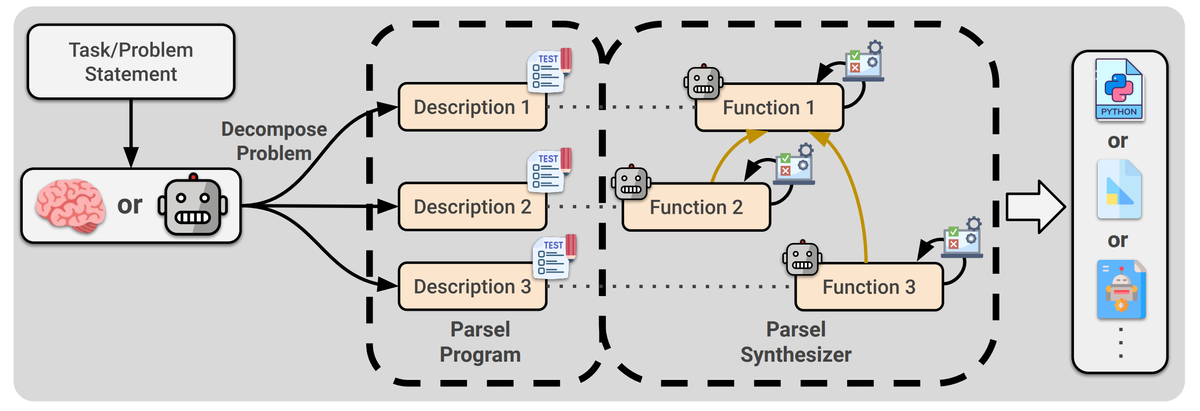
Your request has been blocked due to a network policy.
If you're running a script or application, please register or sign in with your developer credentials here.
Additionally make sure your User-Agent is not empty and is something unique and descriptive and try again.
if you're supplying an alternate User-Agent string, try changing back to default as that can sometimes result in a block.
if you think that we've incorrectly blocked you or you would like to discuss easier ways to get the data you want, please file a ticket here.
55 минут назад @ reddit.com![[P] GPT-Burn: A simple & concise implementation of the GPT in pure Rust 🔥](https://external-preview.redd.it/zyy82Jzf0tKuY3-zML-vBDNTppNMNTjtkMNMFjFURYw.jpg?width=640&crop=smart&auto=webp&s=c7de4d19b9e2ebea003a7a66d64855b6cd202204)