Rethinking Text Resizing on Web
Rethinking Text Resizing on Web
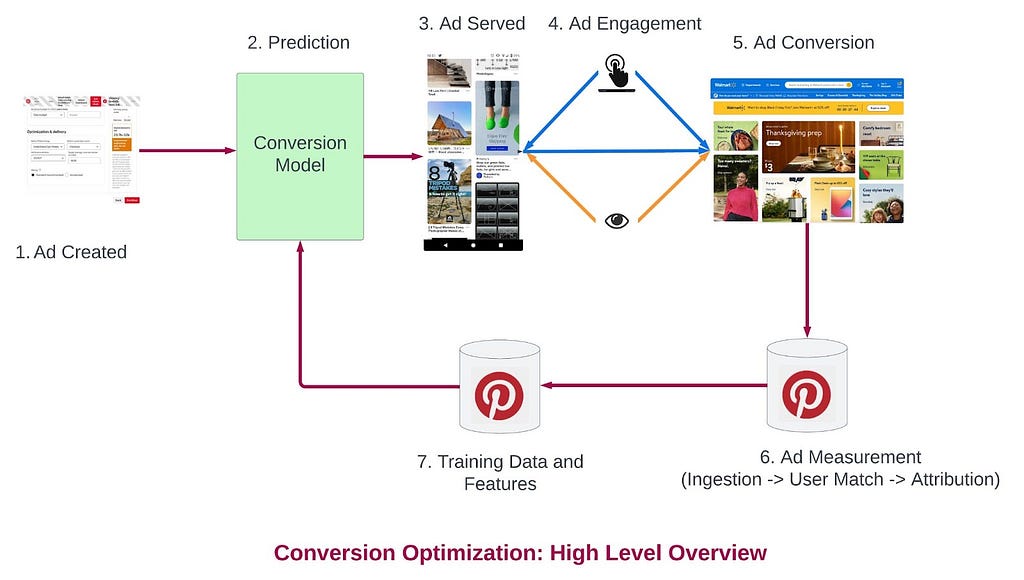
Airbnb has made significant strides in improving web accessibility for Hosts and guests who require larger text sizes.This post takes an in-depth look at:The problems encountered on mobile web when relying solely on browser zoom.The challenges of introducing changes that would impact the workflow of all frontend engineers.The benefits seen since launching these accessibility improvements.by: Steven BassettImproving web accessibility is a critical priority at Airbnb, and we use the Web Content Accessibility Guidelines (WCAG) to help guide our compliance efforts. One area that often leads to accessibility issues is WCAG 1.4.4 Resize Text (Level AA). This guideline, which we’ll refer to as Res…
1 day, 17 hours назад @ medium.com